mongodb单机可靠性比较低,我们投入生产环境往往需要多台服务器的容灾和负载均衡,mongodb推荐使用Replica Sets来进行小的容灾和负载解决方案。我相信很多中小型互联网公司3-4台mongodb服务器的配置无论从抗压和稳定角度来说都已经足够了,至少数据量在千万级以下都不需要考虑sharding分片和cluster集群。
我们公司最近将mongodb投入生产,本文将对架设,模拟灾难(包括断电,断网,数据损坏),修复和客户端(node.js)连接mongodb副本集做一个比较详细的分享,如有错误,欢迎指出,板砖轻拍啊。
[参考资料]
参考:mongodb 官方API http://www.mongodb.org/display/DOCS/Replica+Sets
参考:Kristina Chodorow’s 博客(mongodb开发程序员的博客) http://www.snailinaturtleneck.com/blog/2012/05/07/replica-set-internals-bootcamp-part-iv-syncing/
参考:Kristina 写的3本mongodb书籍 《MongoDB 权威指南》、《Scaling MongoDB》和《50 Tips and Tricks for MongoDB Developers》
参考:noSqlFan上的相关文章 http://blog.nosqlfan.com/tags/MongoDB
1、架设
我们首先需要3台mongodb服务器,(除去仲裁服务器,最好是4台,之后会说明,这里我是用了mongodb v2.0版本),作为最基本的mongodb副本集搭建基础,还要保证这3台服务器网络互通。
a\启动
首先我们分别启动3台mongodb,命令如下:
四台mongodb服务器的ip分别为:10.1.10.31, 10.1.10.28, 10.1.10.30, 10.1.49.225(仲裁服务器)
mongod –replSet wzh –rest –dbpath /usr/local/wzhdb/ –journal –port 10001
简单说明一下:
–replSet wzh:表示副本集的名字为“wzh”,这里的名字可以任意取;
–rest:是打开web监控页面,比如我们这里监听10001端口,则打开http://10.1.49.225:11001/就可以看到这个mongodb数据库进程的信息
–journal:打开日志,我们这里模拟生产环境,所以建议将日志打开,以防不测。日志将会记录在/usr/local/wzhdb/journal/下,也就是你的数据库目录下(仲裁服务器不存储数据,不用打开此选项)
另外:这里没有使用后台运行,为了便于查看连接,我尽量模拟生产环境。
b\初始化
我们现在暂时将10.1.10.28作为master,于是我们用mongo命令登录10.1.10.28,来初始化副本集。
有3种方式可以初始化一个副本集:
1、db.runCommand( { replSetInitiate : <config_object> } )
2、rs.initiate(<config_object>)
3、rs.initiate()//先初始化,再通过rs.add等方法修改
这里的config_object会记录在local.system.replset这个集合内,这个集合会自动的在副本集成员之间广播,而且我们不能直接修改他们,需要使用命令来改变它,例如(replSetInitiate 命令)。
我们来看下config_object可以包括那些东西,下面是一个config对象的例子:
1 | { |
详细说明:(默认值在括号中)
1 | _id:副本集的名字,必须和命令行的名字匹配,也就是您刚才启动mongodb数据库命令行的那个名字,数字字母,不能包含"/"; |
接下来我们来介绍下rs命令:在命令行我们输入
1 | rs.help() |
命令就不翻译 了,我们现在建立一份配置文件,然后启动它,启动我们的mongodb副本集:
1 | vavar conf = { |
执行后出现:1
2
3
4{
"info" : "Config now saved locally. Should come online in about a minute.",
"ok" : 1
}
等1分钟整个副本集就正常启动起来了。
我们打开后台的副本集控制台看下:

28是主,30和31是从,而我的虚拟机225则作为仲裁服务器在这个副本集中。
2、测试副本集同步
我们的副本集已经正常启动起来了,我们来测试一下副本集启动的情况吧,我们直接连上28,发现命令控制行的前缀变成 了:
1 | PRIMARY> |
这里我们往test集合里插入了10W条数据,为什么要带tags的key呢,我是为了另外一个篇文章所用的,利用mongodb做分词检索1
2PRIMARY> db.test.find(); //0.25GB的数据
PRIMARY> db.test.count() //100000
主服务器的10W条记录已经成功插入了,我们看下另外2台secondary的节点
分别连上30和31服务器
运行1
2SECONDARY> db.getMongo().setSlaveOk();
SECONDARY> db.test.count()//100000
发现数据已经完全同步过来了
3、删除和增加
如果相对副本集进行扩容,想加入一台mongodb服务器进入副本集,我们首先需要启动这个节点,最好是将数据事先拷贝一份启动,不然一个新的空的数据库进来同步可能会复制过多的数据而导致应用奔溃。
我们登录28服务器,先将30服务器去掉。1
PRIMARY> rs.remove("10.1.10.30:10001");
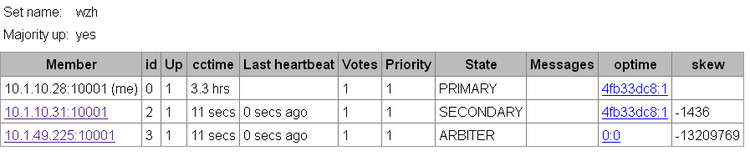
观察副本集的状态,发现只剩下3台了,于是我们再往28服务器插入1000条数据
1 | var tags = ["nn","nn","vv","yy","ii","kk","gg","ee","aa"]; |
1000条数据是瞬间插入完成的。这样28和剩下的31服务器上就有了10W1000条数据了。
接下来我们把30服务器加回去,登录28服务器:1
2PRIMARY> rs.add({_id:4,host:"10.1.10.30:10001"});
{ "ok" : 1 }
将30服务器加回去,启动30上的mongodb;我们看下新加的1000条数据有没有同步过去了。登录30服务器1
2
3SECONDARY> SECONDARY> db.getMongo().setSlaveOk();
SECONDARY> db.test.count();
101000
就是这么简单,新加入的节点已经可以同步数据和正常工作了。
2、容灾
1、单个节点意外崩溃
现在副本集中28是主,30和31是从,所以我手动将28的mongodb进程kill掉,看看整个集群是否还可以正常运作。
大约几秒钟,mongodb仲裁服务器选举出了一位新主人:
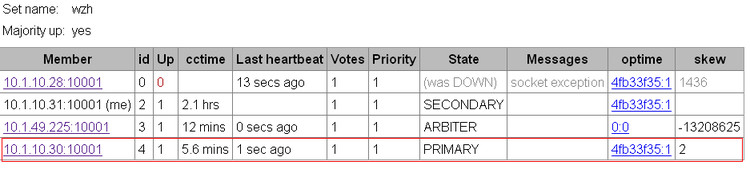
然后我们往新的主节点30插入1000条数据。1
2
3
4
5
6
7PRIMARY>
PRIMARY> var tags = ["nn","nn","vv","yy","ii","kk","gg","ee","aa"];for(var i=0;i<1000;i++){
... db.test.insert({"name":"groupa","tags":tags})
... }
PRIMARY>
PRIMARY> db.test.count()
102000
现在我们一共10W2000条数据了,很快模拟故障修复了,我们正常启动28节点了,很明显30节点当老大很爽,不愿意将老大的位置再让回给28了:
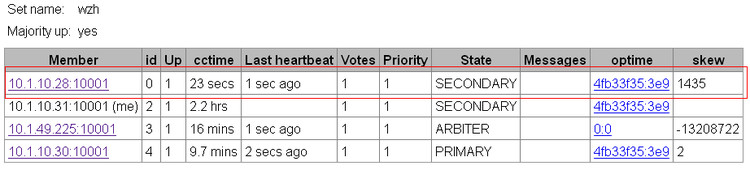
经过查询,发现28节点的数据也已经是10W2千条了,在28down的过程中,新增加的1000条数据已经同步过去拉。
2、同时意外崩溃2个节点
我们现在同时将副本集内的2个节点kill掉,模拟一个比较大的灾难。
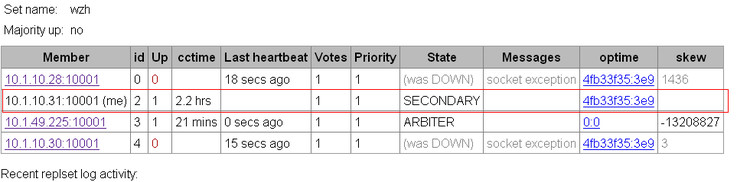
上图可以看到只剩下31一台节点苦苦支撑了,另外2个兄弟已经down了,这时副本集中可用的数据节点只有1个了,仲裁服务器无数据的,所以自动降级为secondary,这时整个集群只可读,不可写。我们尝试往31数据库插入一些数据.1
2
3
4SECONDARY> var tags = ["nn","nn","vv","yy","ii","kk","gg","ee","aa"];for(var i=0;i<1000;i++){
... db.test.insert({"name":"groupa","tags":tags})
... }
not master
曝出了不是master的错误,之前在secondary上也是无法进行写操作的。之后修复问题或者网络,重新启动28和31的进程,就又能回复正常了。
3、衰到家了,其中一台硬盘数据损坏
我们现在模拟硬盘数据丢失的情况,比如我们的应用已经跑了一段时间了,突然30节点down机了,发现硬盘数据损坏了,我们的mongodb数据也全部丢失了,幸好我们当时建立了集群有其他兄弟备份着。
我们对30节点换了一块新硬盘,装好了系统以后准备加入这个集群,但是,且慢!
我们可以让集群中的一台服务器比如31,先脱离集群,然后将数据文件拷贝到30上,然后将30和31再加入集群,这样就不至于数据相差太大,同步过久导致整个应用缓慢或者崩溃。
这里就需要我们对副本集设置4台机器了,1台崩溃了,1台去修复了,还有2台正好1主1从抗住应用。所以如果只有3台的话,当副本集只剩下1台节点会进入secondary,就无法写入操作了,无法正常运行应用了。
总结一下具体步骤:
1、将副本集中的某一台机器A脱离副本集
2、将这台A机器的数据库文件夹copy到新安装的B机器上,或者启动mongodb副本集让这2台机器慢慢的同步,这样脱离应用的副本集同步不会拖慢整个副本集
3、同步完成以后分别将A和B机器加入到原来的副本集中即可。
3、客户端代码连入mongodb副本集
mongodb副本集主要是为了容灾备份和负载均衡用的。我们一般的互联网应用大多是读多写少,所以mongodb副本集只有一个主,而有多个从。那我们的客户端代码如何正确的连入mongodb副本集呢?下面我就以node.js利用rrestjs框架 和 node-mongodb-native 模块进行mongodb副本集的操作。
rrestjs框架官网:http://www.rrestjs.com/
官方帮助文档地址:https://github.com/christkv/node-mongodb-native/blob/master/docs/replicaset.md
只需要将rrestjs的配置文件按如下配置即可:1
2MongodbRC:'wzh',//如果是false表示不使用mongodb的副本集,否则为字符串,表示副本集的名称
MongodbRChost:['10.1.10.28:10001','10.1.10.30:10001','10.1.10.31:10001'],//表示mongodb副本集的ip:port数组。
然后正常使用您的应用,插入查询等操作,rrestjs自动会帮你连入mongodb副本集了
成功的插入了mongodb副本集数据并返回了刚才插入的内容。